
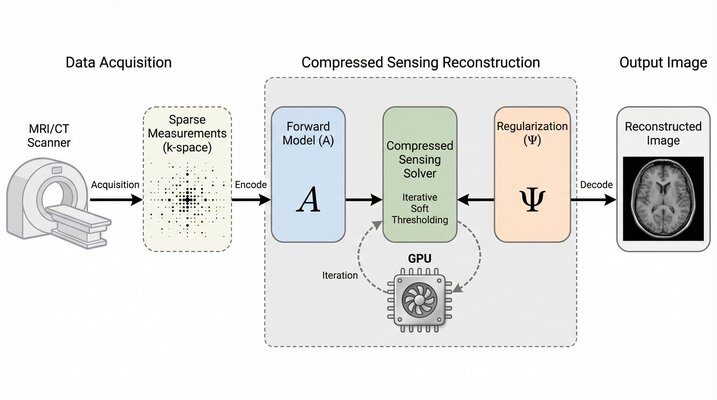
Compressed Inference
Compressed Inference applies compressed sensing theory to GPU-accelerated medical imaging. The project develops efficient reconstruction algorithms that recover high-quality images from fewer measurements, bringing advanced imaging capabilities to resource-constrained clinical settings.
