
AI Alignment
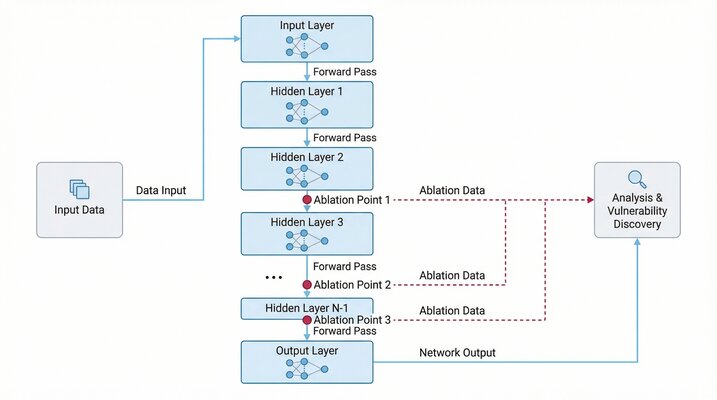
AI Alignment investigates failure modes in large language models through ablation-based analysis and security vulnerability discovery. The project combines adversarial red-teaming with alignment research, systematically probing models to understand how they break and how to make them safer.
